
Piotr Wawrzynów talks us through the process of creating a tool that profiles coaches in a similar manner to how you might profile players.
I love talking about coaches: their ideas, approaches, philosophies. One of my favourite things is assessing a team’s early performances and trying to predict whether the coach will succeed long-term. At some point, I even stopped following teams and started following coaches. You’ll find me wherever the good coaching is. But what exactly is “good coaching”? How can we tell that the coaching is “good”?
I always felt like there was not enough attention paid to coaches in the public space so I decided to take matters into my own hands. Guided by the vague memory of Tom Worville’s search for the next Manchester City manager, I attempted to develop an objective method for profiling coaches with data in a way that could support recruitment processes.
Fundamentally, I wanted to create a model that looked behind the scoreline and, as much as possible, ignored the quality of available players. On top of this, I wanted to emphasise the concepts of repeatability and versatility. When hiring a new coach, we should make sure that what made him successful in the past, is easily reproducible. And as much as adaptability is also important, we should stay aware of the risks associated with employing someone whose ideas are heavily suited for a certain set of players or a specific environment.
When using this model, it is important not to overstep its parameters. Used correctly, it will help to highlight red flags, identify anomalies, ask proper questions and disqualify the candidates who definitely shouldn’t be hired. Beyond that, there need to be clearly defined expectations, thorough eye-testing, further research, and finally – a proper interview process.
In effect, my project is not that dissimilar from what has already been done in the world of player profiling—I have distinguished between performance (the output of a coach) and playstyle (the ideas that structure the coaching).
In the end, I created a tool that allowed me to aggregate all this information into an easy-to-use dashboard. Here’s the profile for Mauricio Pochettino from his tenure at Tottenham:
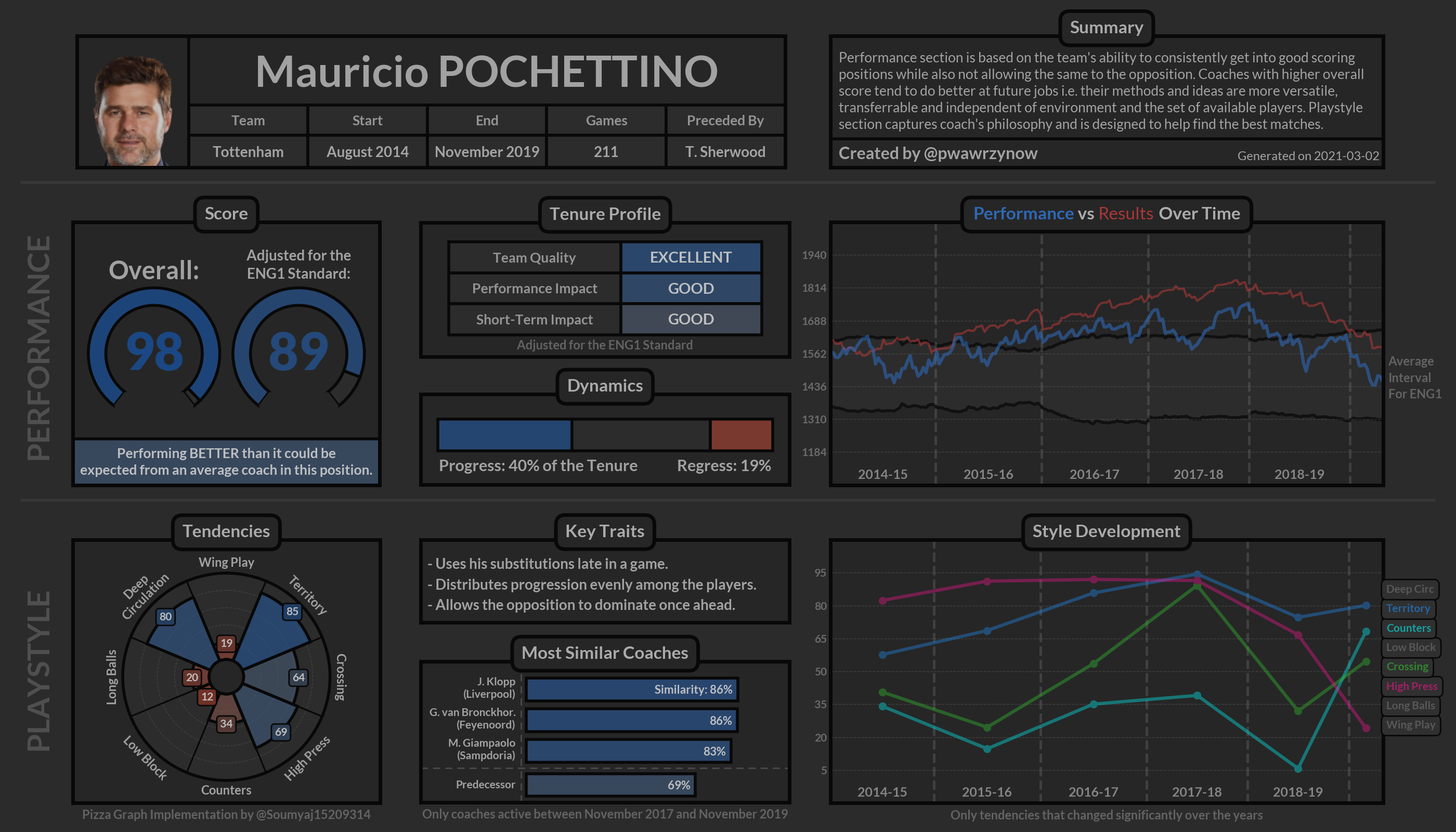
In the rest of this piece, I’m going to talk you through how I built this tool. If you want to find out more about this project, you can get in touch with me on Twitter @pwawrzynow.
Performance
To quantify a coach’s impact upon a team, I wanted to create a system that would meet the aforementioned criteria while also being easily trackable in time and allowing a comparison between leagues.
My first choice as a basis for this system? An Elo rating. You can read the theory here. The reason for sharing this particular resource is that it also guided me through the eventual implementation process.
For those of you who don’t know, an Elo rating ranks teams on a result-by-result basis. After playing, winners receive N points and losers are punished with -N points, where N is a number determined by multiple factors, the most impactful of which is defying pre-game expectations. It’s more rewardable for West Bromwich Albion to beat Manchester City than Fulham and, conversely, it’s more harmful for Manchester City to lose to West Bromwich Albion rather than to Liverpool.
This concept in its basic form was used to create the Results Rating which itself serves only as a context provider for the real star of the show – the Performance Rating.
The main concept behind the Performance Rating doesn’t change—it’s still an Elo-based system—but this time, the winner and the loser get determined based not on goals but on a custom xT-based performance metric. xT (Expected Threat) is a really nifty framework for valuing on-ball actions. It was created by Karun Singh and you can learn more about it here.
My performance metric essentially looks at the quality of opportunities created throughout the game and weights them based on their possible impact on the scoreline. What does this look like? For example, a through ball played into the box in the 80th minute will, in a grand scheme of things, matter more when it’s still 0:0 (or 1:1, 2:2…) rather than when a team is already ahead or behind by 2, 3, 4… goals.
This adjustment accomplishes two things:
1. It does not undervalue coaches whose main plan consists of killing the game early, dropping deep and happily conceding opportunities
2. It does not overvalue coaches who rely on a game state to create, i.e. those coaches whose teams are able to create only when already losing and the opposition is not pursuing goals as hard
To sum up, the Performance Rating rewards coaches whose teams consistently get into better scoring positions than their opponents but who do not necessarily score more goals than them or even take better shots.
But, you might ask, why do we need a second, more complicated rating? Aren’t good old results enough? To answer this, let’s take a peek at some current fixtures. Recently, Borussia Mönchengladbach lost 1:3 to Augsburg. On the basis of the threat produced by each side, this doesn’t seem like a particularly fair outcome:
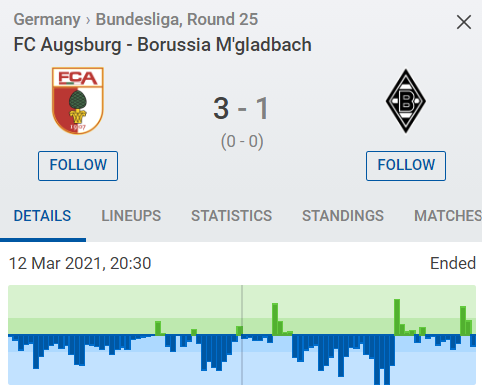
[Source: SofaScore]
Games like this happen almost every weekend. The favourites seem to have all the resources necessary to win. They protect the goal well enough, enter the box relatively freely but lack the final touch that would put the ball into the net. Then, at the other end, a random moment of brilliance, a counter-attack or a set piece, happens and all of the good football is wasted. Should we punish coaches in such cases?
To make an actual long-term example out of this, it might be a better idea to sign Graham Potter who consistently underperforms his Performance Rating (the reasoning being that if he’s able to make his current players enter valuable positions on a consistent basis, it wouldn’t be a problem to recreate this with any squad) rather than Sean Dyche who overperforms it (making his ideas seem tailored for the particular Burnley environment, increasing the uncertainty of whether he would be able to repeat the results somewhere else).
Using these two concepts—Results Ratings and Performance Ratings— you can then produce a timeline of a coach’s tenure at a club. Here you can see Mauricio Pochettino’s tenure at Spurs represented:
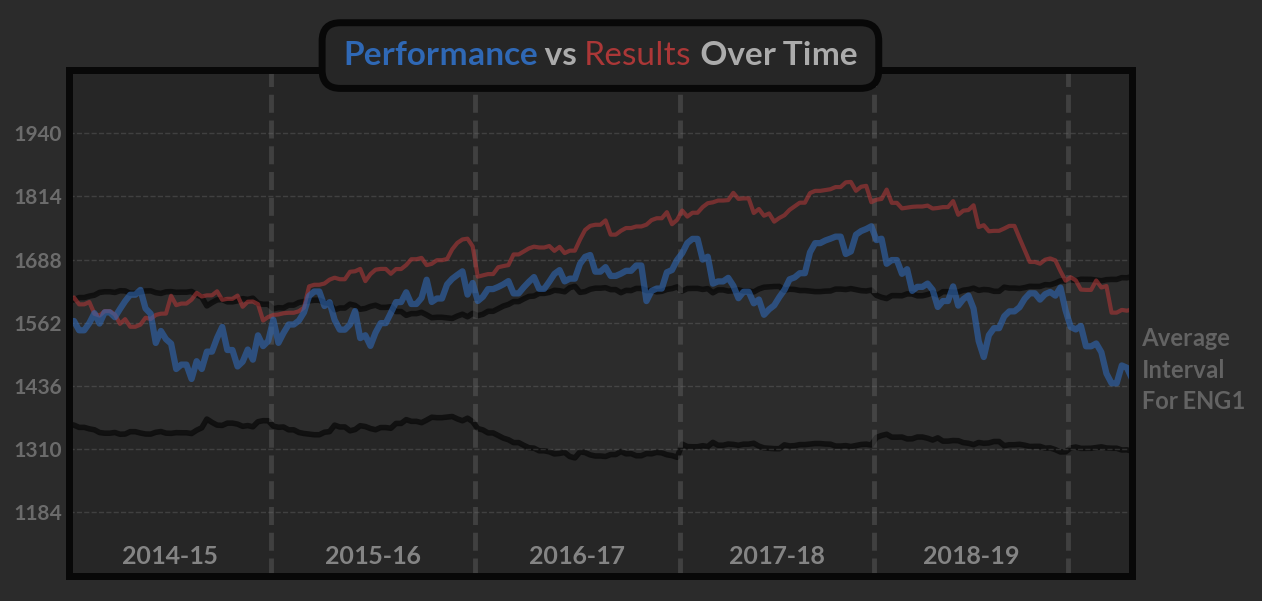
The plot used here is pretty self-explanatory: it shows how the results and performance of the team changed over the tenure. The average interval going through the middle serves as a point of reference against the league’s strength and represents two standard deviations centered around the mean.
Building upon this Foundation
From this base, you can build a toolbox of different metrics that allow you to assess the general abilities of a manager across a number of variables.
Here are the metrics I have developed within my platform:
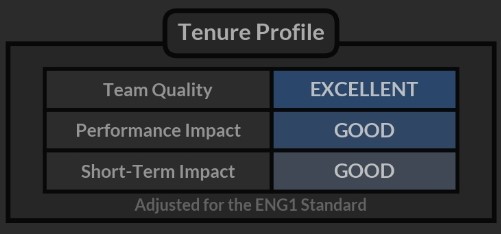
Team Quality – This metric allows us to assess the coach’s average Performance Rating over their whole tenure at a club.
Performance Impact – This metric looks at how the Performance Rating changed over the tenure, making it more apparent whether a coach improved performance, provided some stability or made the team worse.
Short-Term Impact – This metric shows how the Performance Rating changed in the period between taking over until the first pre-season.
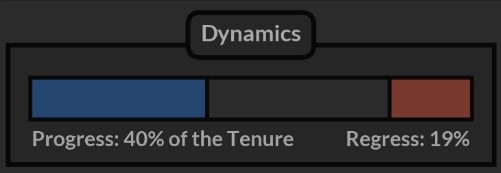
Dynamics – One thing I didn’t like about the Performance Impact metric was that it looked at the rating at the beginning and the end of the tenure, ignoring everything that happened in between which resulted in undervaluing coaches who were improving ratings for the most of the time, only to make them drop near the end.
To deal with this, I developed a method designed to identify prolonged spells of good and bad performances and presented them as a percentage of the whole tenure. This way we’re able to tell that Mauricio Pochettino was improving Tottenham’s Performance Rating 40% of the time, making it worse 19% of the time and keeping it relatively at the same level for the remaining 41%.

Overall Score – Even though it will never tell a complete story, it’s still nice to have this convenient, almost FIFA-like overall score which main use would be to filter big datasets and separate good and bad coaches.
I used the following recipe to build the Overall Score:
- 60% of the Team Quality
- 30% of the Performance Impact
- 5% of the Progress (Dynamics)
- -5% of the Regress (Dynamics)
Exchange Rate – The general level of the Performance Rating is highly influenced by the strength of the league, making nearly all the coaches from outside the top five leagues in Europe greatly undervalued.
That’s why I included a second overall rating where I present the same score but compared to the coaches from the same league, providing at least some reference point for the environment.
Overall Assessment – The league’s strength wasn’t the only source of confusion in these scores. As it turned out, reliance on Team Quality in calculations made impactful coaches from worse clubs also look worse than the eye-test suggested.
To deal with this, I built yet another model that tried to predict how well the coach should do based on the state of the team in the final months of the predecessor’s tenure. This way, I was able to specify precisely whether and by how much the expectations were defied. The result of this calculation is presented as a text in the bottom of the Score panel.
For those who are not yet convinced that this produces a different kind of information than the Performance Impact metric, I want to clarify that here we’re dealing with a more sophisticated mechanism than a one-dimensional difference between two ratings. Based on the historical data, the model learns about relationships between different metrics and auto-adjusts its output for different cases e.g. it expects less from the average coach if the predecessor recorded a higher impact.
Playstyle
Throughout the course of this project, I realized that coach recruitment is more about risk management than anything else. Putting extra effort into finding the right person—one who fits the club’s philosophy and players’ profiles—might, in the grand scheme of things, reduce the number of resources needed to be spent for adaptation purposes or squad’s revamp.
To boost this aspect of the recruitment process, I tried to describe playstyle and coaching philosophy :
Tendencies
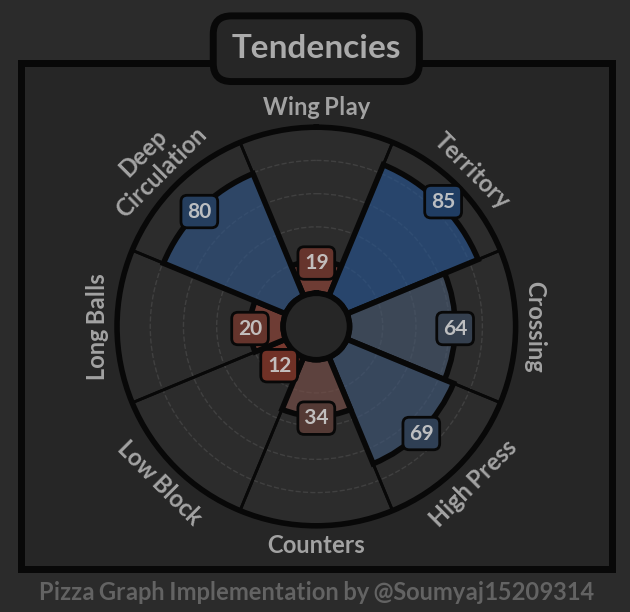
I like to think of playstyle in terms of volume of actions rather than the success of these actions. With that in mind, I developed eight quantitative metrics that capture the way of playing and allow to differentiate between types of coaches:
Long Balls – a metric describing how direct the team is when in the defensive area on the field, including behaviour on goal kicks, clearances or under high pressing.
The location of the defensive area is determined by the team’s playing height but usually it includes the first 25 meters along the height of the field.
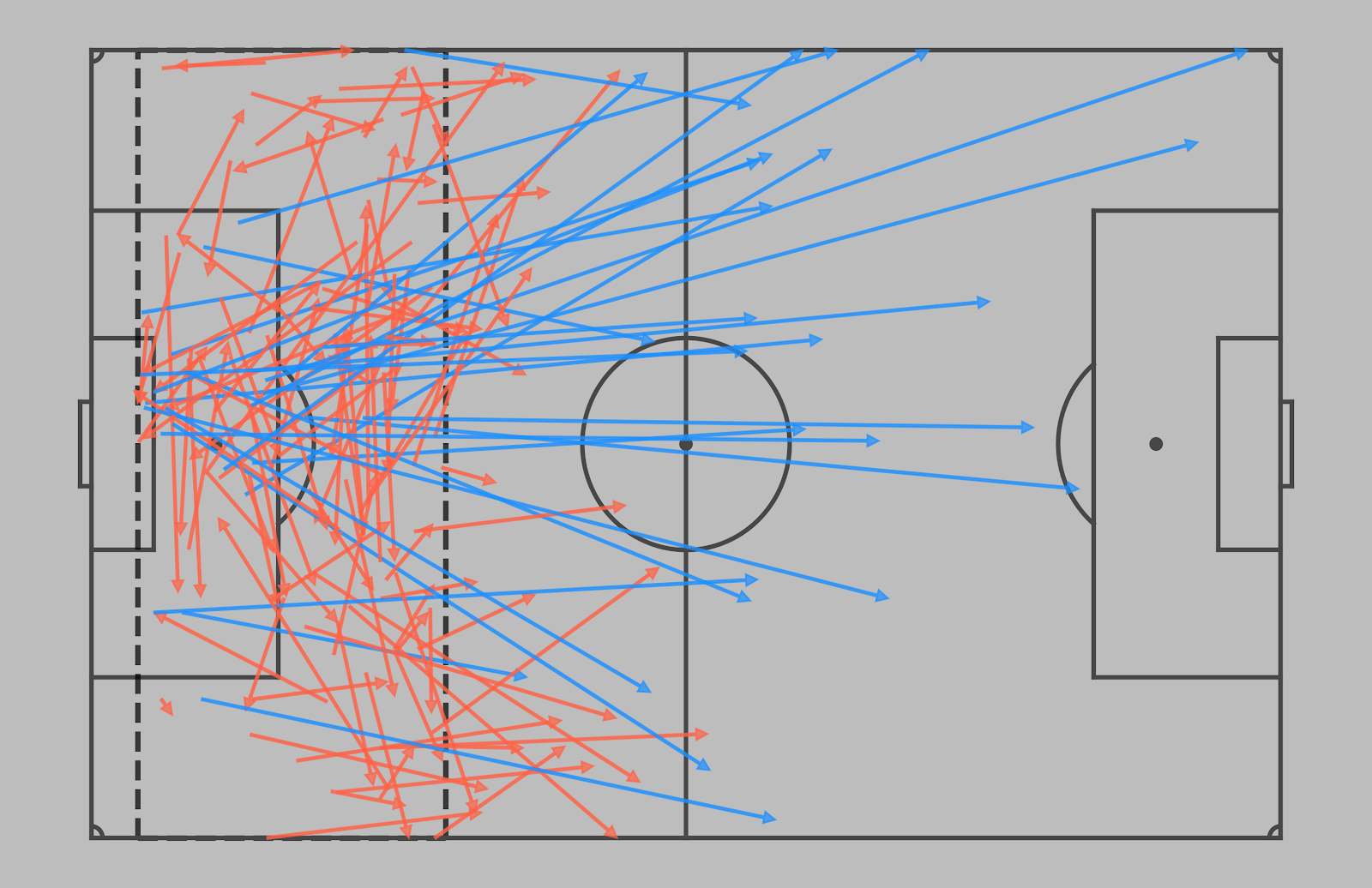
[Example of the passes started in the defensive area. Direct passes marked in blue]
Deep Circulation – represents the tendency to move the ball around the back as opposed to launching a long ball or making a forward pass.
The definition of a build-up zone is, once again, dependent on the team’s playing height and is usually located around the middle third.
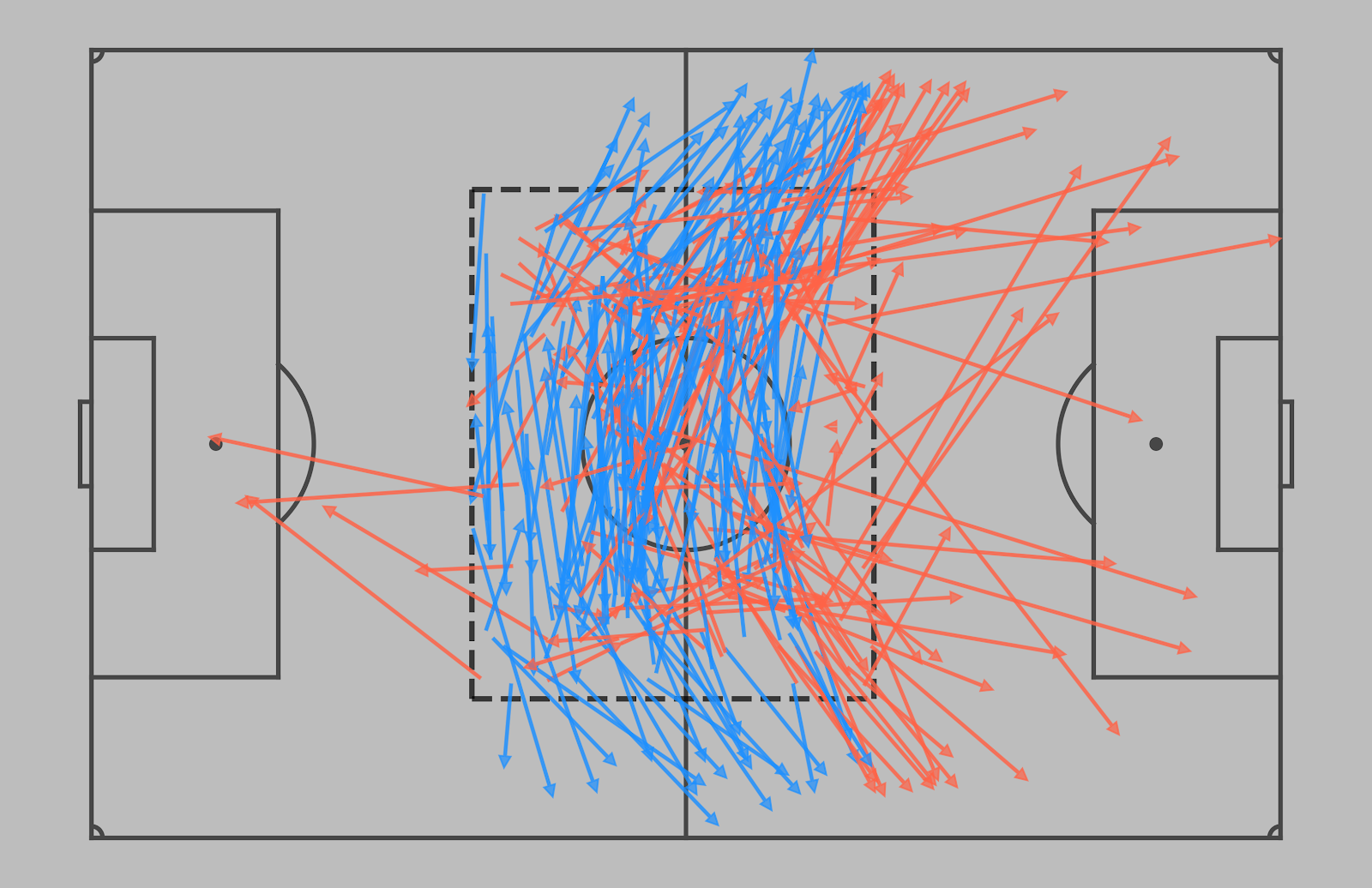
[Example of the passes started in the build-up zone. The ones used in deep circulation calculations are marked in blue]
Wing Play – a tendency to concentrate the play on the wings. It is calculated as a share of passes that escape the build-up zone through the wide areas.
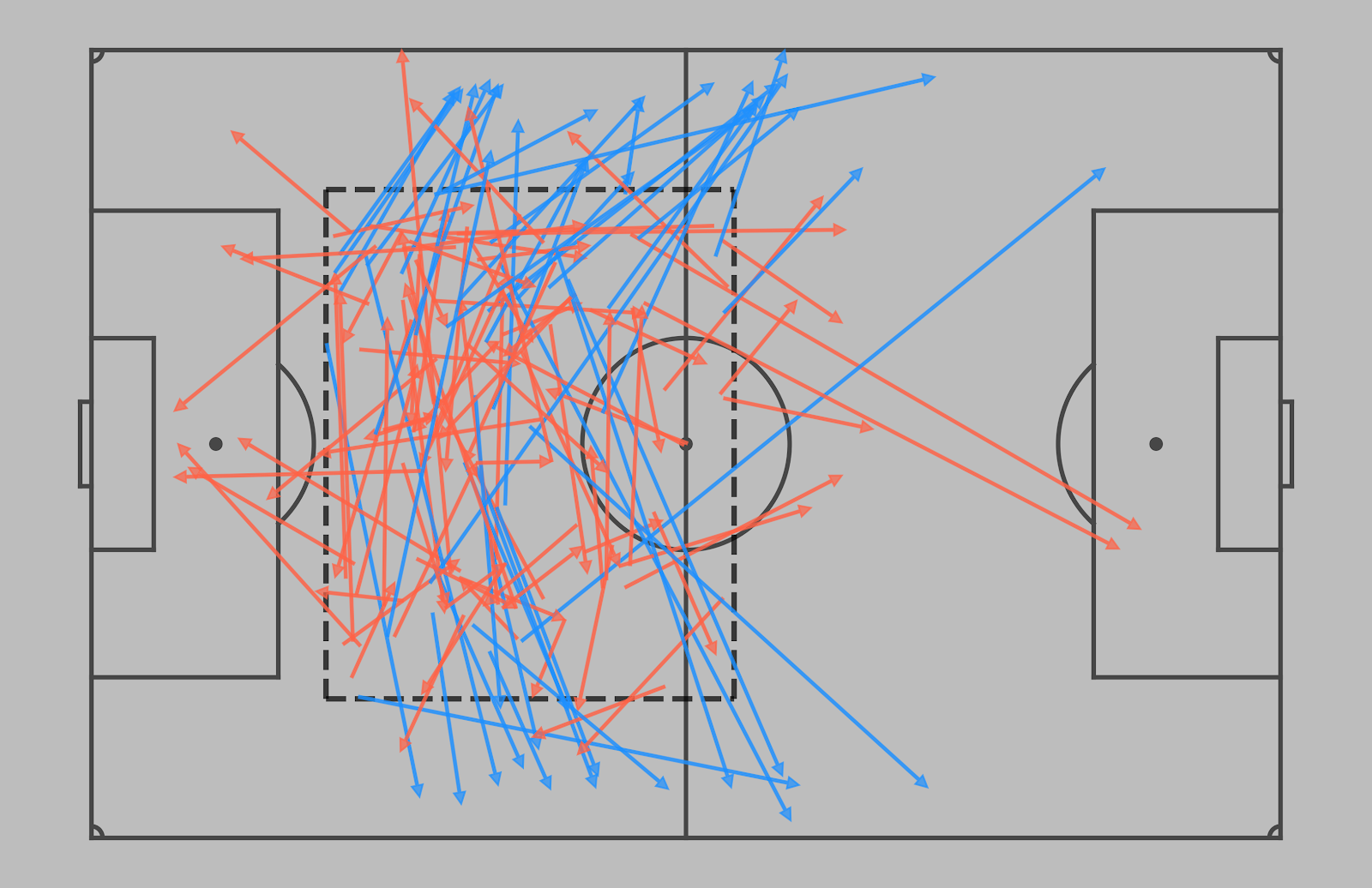
[Example of the passes started in the build-up zone. The ones that qualify as the wing play are marked in blue]
Territory – the tendency to enforce territorial dominance. The calculations are based on the field tilt (team final 3rd passes/team and opponent final 3rd passes).
Crossing – a team’s tendency to enter the box via crosses (as opposed to entering in other ways).
High Press – this metric describes a team’s pressing intensity (based on PPDA).
Counters – the tendency to move the ball quickly upfield right after regaining the possession in the defensive half. Worth mentioning that this metric is not taking the absolute volume into the account. The team that counters a lot but still prefers to keep the ball or is unable to progress quickly, will have a lower value here.
Low Block – the tendency to drop into a passive block while defending.
I tried to include some other metrics here like e.g. verticality or tempo but they were either very difficult to implement with event data or not bringing any new information to the party.
Style Development
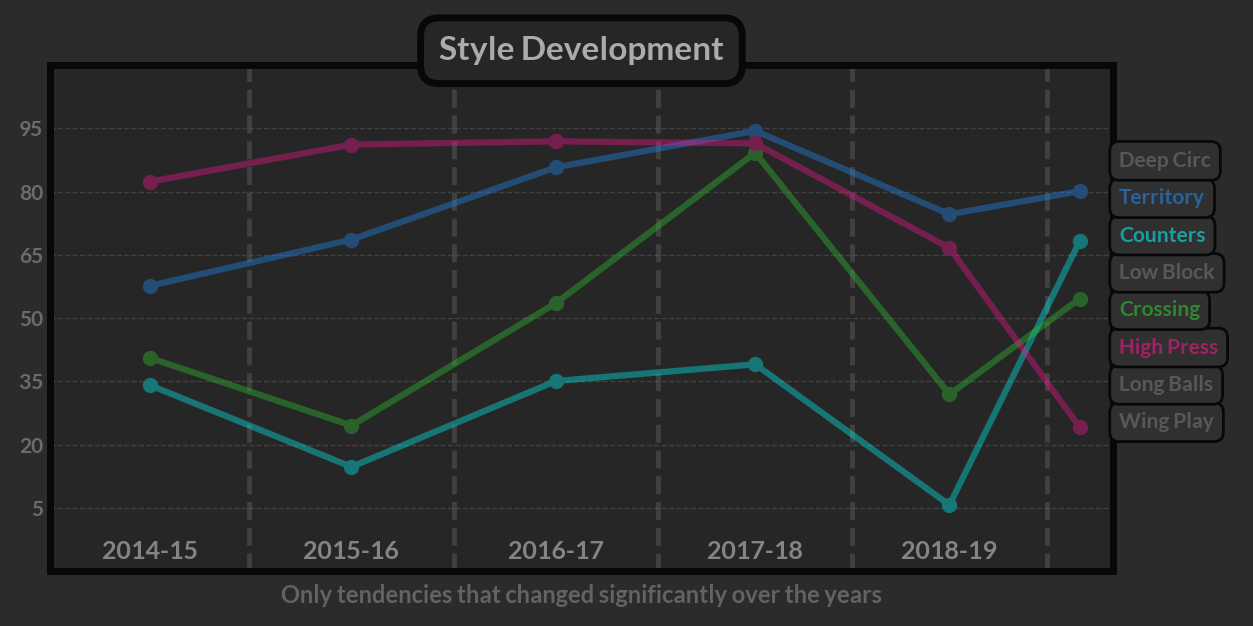
This visualization helps to accomplish a few things but mainly serves as a way to show how the tendencies developed over time and provides some answers for the anomalies detected on the performance rating plot. With Mauricio Pochettino as an example, it’s actually fairly easy to connect radical changes in the playstyle with the drop in performance.
Similarity
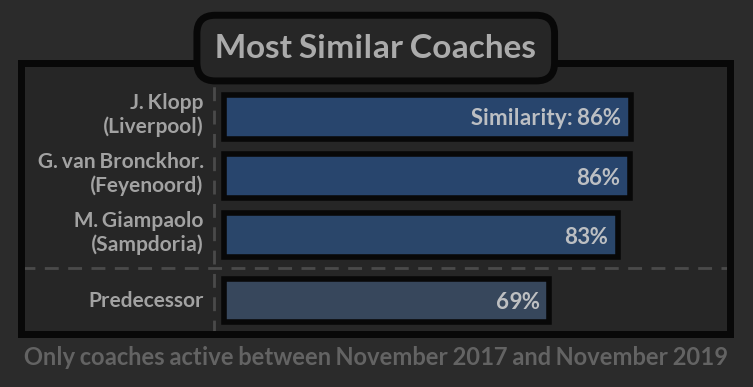
The concept of similarity plays a huge role in the filtering process for a recruitment department. It can allow us to identify coaches that fit the club’s philosophy, match the predecessor’s perspective on football or, if we’re ready for the transformation, simply play in a way we want to play. This part of specifying the expectations and making sure we stay aware of what future risks are associated with each choice might be the key to success in the whole process.
If you’re interested in the technical details here, I used the Kolmogorov–Smirnov Test that looks at the whole distribution rather than individual aggregated values and, at least to some extent, helps to overcome the associated information loss.
Key Traits

Even with stylistic tendencies accounted for, I felt that there was a level of a coach’s approach to gameplay that wasn’t being accounted for. As a result, I added a Key Traits section to the dashboard to cover the peculiarities of a coach’s in-game management style.
These traits cover:
Game state reliance highlights how the coach’s approach changes with game state.
The coach can e.g. influence the team to dominate irrespective of a scoreline or fail to do so, resulting in domination only when already behind. The opposite approach would be to allow the opposition to dominate at all times or to do so only when already losing.
The calculations are, again, based on the field tilt concept.
Substitutions if consistently done very early or very late in a game will result in an appropriate trait appearing.
Set piece reliance describes how many opportunities a team creates via set pieces or, on the contrary, in open play.
Progression centrality highlights the approach regarding the distribution of progressive events between players which can be either concentrated on a few key ones or spread more evenly.
Freedom describes how much positional freedom the coach allows while attacking. The calculations here were based on the Freedom Rating by @nandy_sd.
Where To Go From Here?
In the long run, I don’t really think that an Elo system is the best choice for the job. Rewarding the winner with all the points and punishing the loser every time might not be entirely fair. For instance, if both teams played horribly we would still reward one of them and likewise, if both played well, we would still punish one. Perhaps more importantly, since there is no direct connection between my performance metric and the outcome of the game, the teams won’t be pushing to accumulate more of it, making the rating updates after very tight games questionable. There is clear room for improvement.
Beyond this, I’d like to look into different methods for rating teams that would track attacking and defensive performances separately while also allowing to deal with promotions and relegations in a more seamless way. There is no such concept in the current system. For example, Daniel Farke 2017-2019, Daniel Farke 2019-2020 and Daniel Farke 2020-2021 would be three completely different entities.
If you want to find out more about Piotr’s project, you can contact him on Twitter @pwawrzynow.
Header image copyright Majed Monam / Shutterstock.com





